

Spotify Skip Prediction Project
Problem Definition
In 2019, Spotify held a Datathon which’s task was to predict whether Spotify user will skip last song of their listening session. The data provided by Spotify contains two distinct datasets:
- 10,000 Listening Sessions
- 50,704 different tracks
Our response variable is a Boolean which means this is a binary classification problem.

The Data
Data Preparation
-
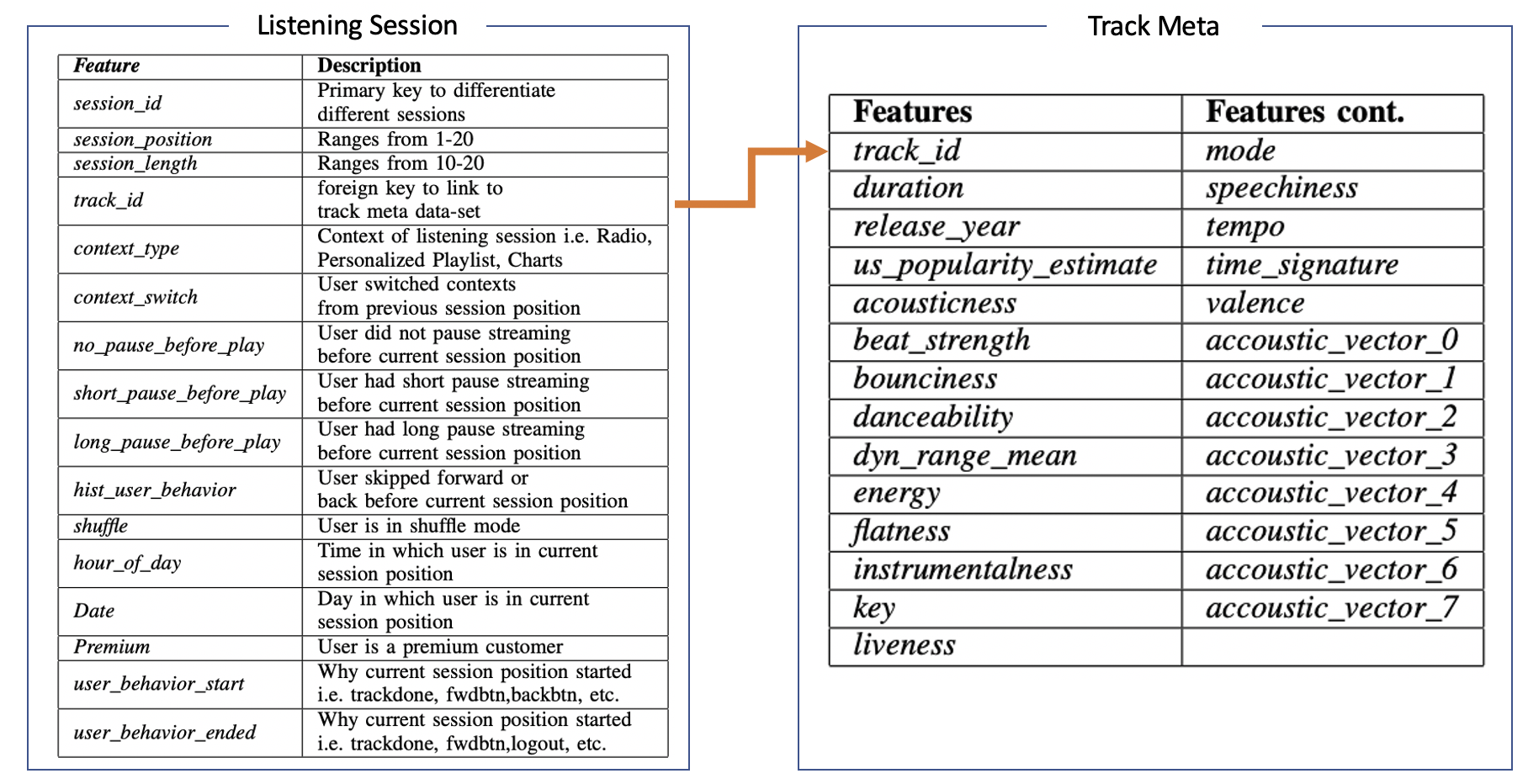
Merging Datasets: The first part of our Data Prepro- cessing step was to combine both of our User Log and Track Meta data-sets using their linking feature “track_id”. After combining these two data-sets, our final data-set ended up having a total of 167,880 rows and 50 columns.
-
Categorical Variables: Next was to tackle our categori- cal features. All 7 categorical features were One-hot Encoded due to the fact that they had no ordinal characteristics. After One-hot Encoding our 7 categorical features, we had a complete data-set of 167,880 rows and 69 columns.
-
Feature Scaling: Features from our Track Meta ranged from decimal values to values as high as 100,therefore, we decided to scale them to values within [0,1].
-
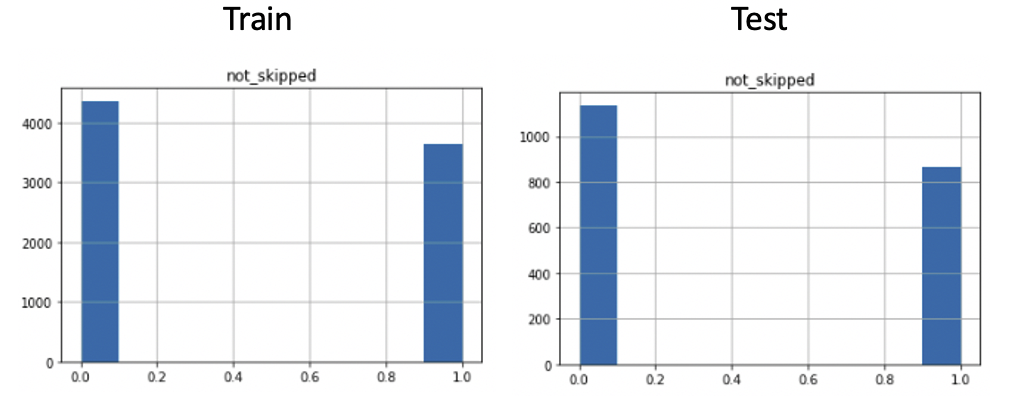
Data Balance: Our data-set does not seem to be severely unbalanced. Figures below show the balance of both our training and testing set, therefore no re-balancing techniques were performed.
Methods
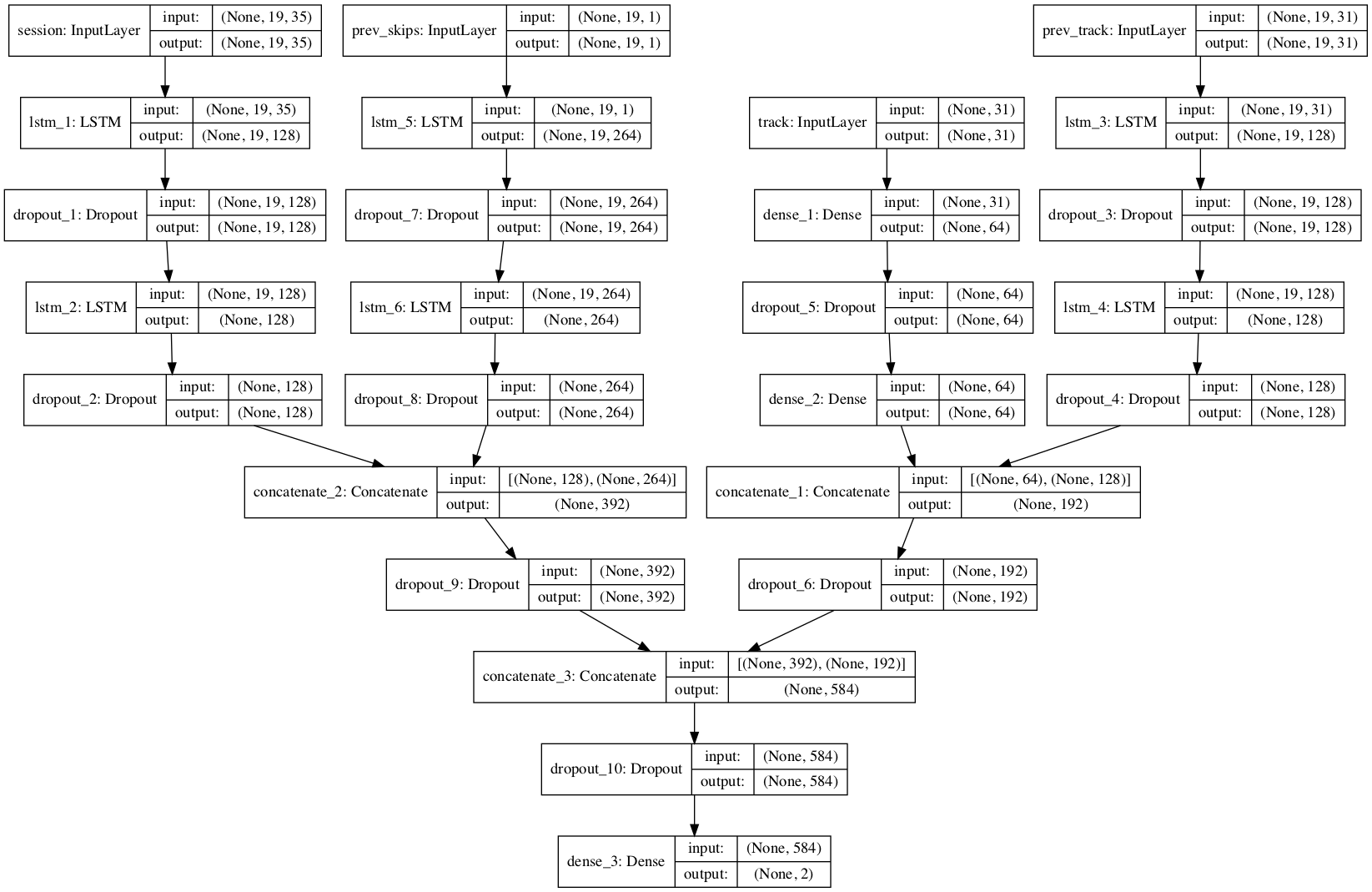
Overall my network consists of 4 different networks with 4 different inputs: Previous Session Logs, Previous Session Track Meta, Previous Skip Sequence, and Last Session Position Track Meta. All four of these inputs will have their own network and I will concatenate them to predict whether the last session position will be skipped.
Inputs
-
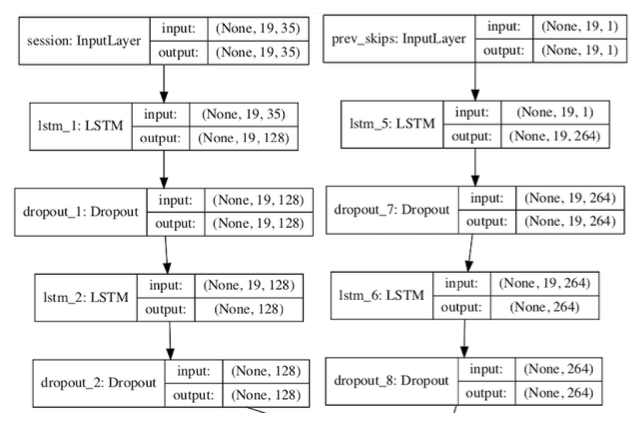
Previous Session Logs: An (19, 35) array that includes all session information leading up to our last session position.
-
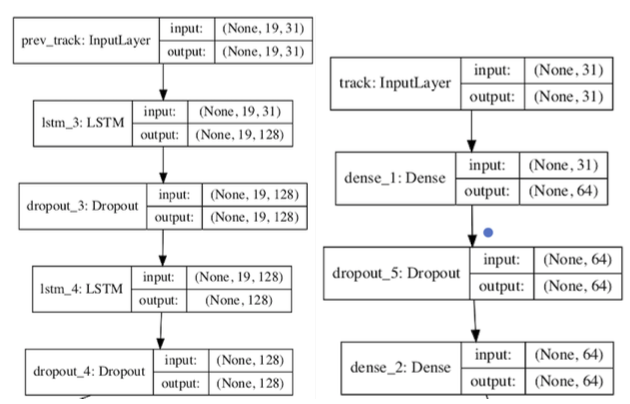
Previous Session Positions Track Meta: An (19,31) array contains all information of tracks listened in session positions < Last Position.
-
Previous Session Positions Skip Sequence: This input is a sequence of 0s and 1s depicting whether tracks were skipped in previous session positions, this input is a (19,1) array. Since we have varying session lengths, we decided to pad the beginning of the sequence with the value “9”. We decided to pad with a value other than 0 due to the fact that in our data, the number 0 means “skipped” and padding our sequences with 0 could alter the performance.
-
Last Session Position Track Meta: Lastly, our fourth input contains all meta information of the track being played in the last session . This is the track for which we are ultimately trying to predict whether the user will skip or not. This is the only input in our model that does not contain any temporal variables.
Network
My architecture consisted of 3 different LSTMs for our inputs containing temporal variables and a Dense Neural Network for our Last Session Position Track Meta input. All four of these networks were concatenated to obtain our final prediction. All networks had varying dropouts ranging between 0.4 and 0.5. Further details on each individual network can be found below.
-
Previous Session Logs LSTM: This model is composed of 2 LSTM layers with a 0.4 Dropout, Relu activation,and 128 Nodes.
-
Previous Session Positions Skip Sequence LSTM: This model is composed of 2 LSTM layers with a 0.4 Dropout, Relu activation,and 264 Nodes.
These two networks were concatenated.
-
Previous Session Positions Track Meta LSTM: This model is composed of 2 LSTM layers with a 0.4, Dropout, Relu activation and 128 Nodes.
-
Last Session Position Track Meta NN This model is composed of 2 Dense NN with a 0.4 Dropout, Relu activation, and 64 nodes.
These two networks were also concatenated.
For the last layer of our model, I decided to go with a Dense Layer with an output of 2 and a “sigmoid” activation function. I chose these two parameters due to the fact that the response variable is binary. Before this last Dense layer, I implemented a Dropout layer with parameter 0.4 in order to avoid over-fitting.
Experiments
Ultimately the parameters that proved to be the most optimal were the following:
- batch_size = 848
- epochs = 100
- optimizer = ’adam’
- loss = ’binary_crossentropy’
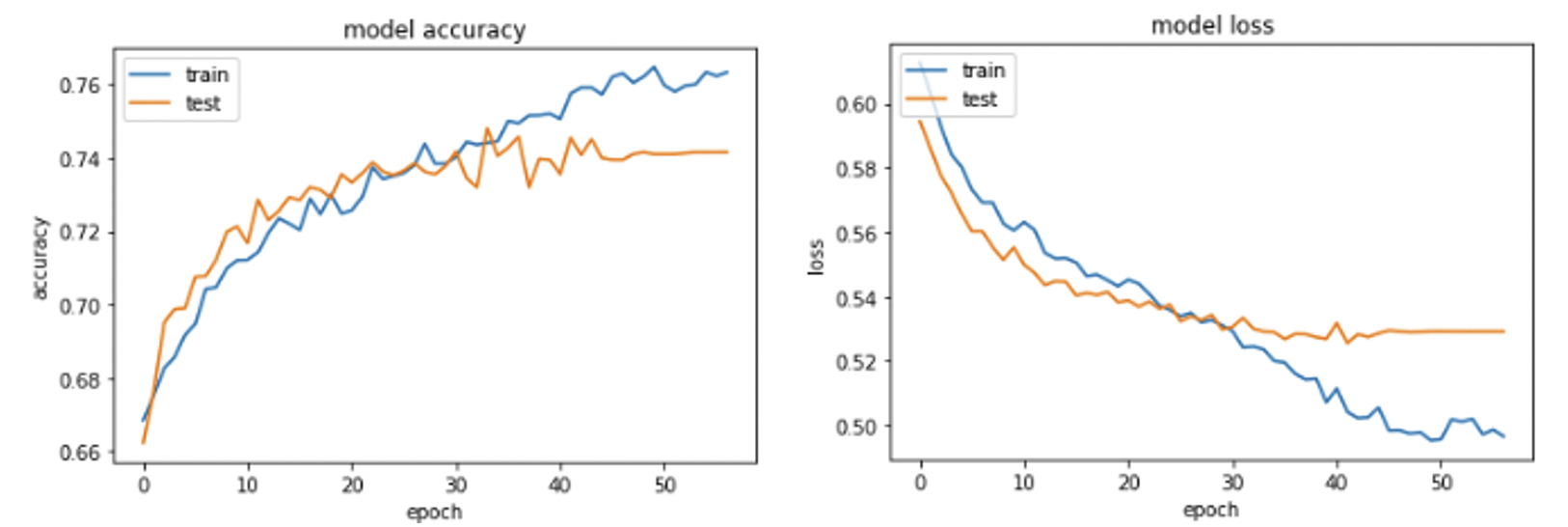
Although our epochs was set at 100, our model stopped training at epoch 59 due to Early Stopping.
The parameters that we noticed had the most positive effect on our model was the batch size and the optimizer. With optimizers such as RMSprop, or model only achieved an accuracy of 54%.
Another experiment conducted was having one single input containing all information about our previous session positions, instead of breaking them up into 4 individual inputs.Thid resulted in an accuracy score of 66% which is much lower than the accuracy obtained by the approach we ultimately went with and discuss in this project.
Results
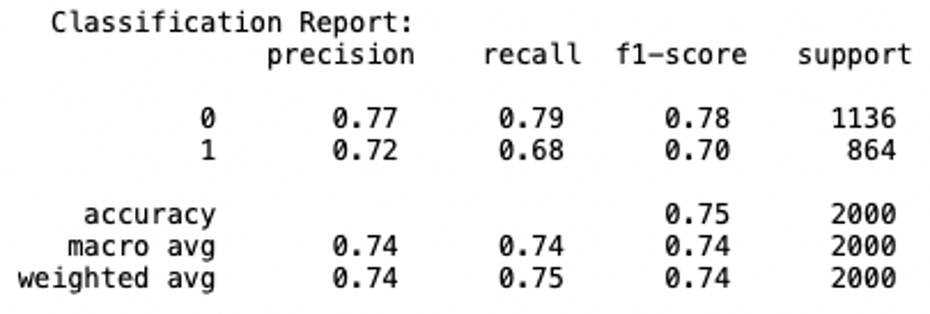
- Our model achieved a Training Accuracy of 76% and Test Accuracy of 75%
- Base line of just predicting 0 yields accuracy of 55%
- One input 2-layer LSTM yield Accuracy of 66%
Conclusion
The model described above has shown significant improvement from the baseline model (0.75 vs. 0.55). My model also had significant improvement from model with single input and one LSTM (0.75 vs. 0.66).
We were able to achieve these results by constructing 4 different models for four different inputs found in our data-set and merging them in order to provide a prediction.
For future work, I would like to tackle the task of predicting whether a user will skip multiple session positions, not just the last one. This type of task will allow me to experiment with NLP techniques such as Seq2Seq encoder/decoder frameworks.